Private data agent · runs on your machine
Ask AI about all your files and databases — privately
Sery is a desktop app that connects every file store and database you have — then lets you search and ask questions across all of it in plain English. It runs on your machine. Nothing is ever uploaded.
Free, open source (AGPL-3.0) · 16 sources · runs fully offline · macOS, Windows, Linux
See how it worksHow it fits together
One agent on your machine. Ask from anywhere.
Sery Link does the work locally. The dashboard and Sery Snap are just the ways you ask — your data never leaves your machine to get there.
Sery Link · desktop agent
Install it on each machine. It connects all 16 sources, parses and indexes them, and runs every query locally. This is the engine — free, no account.
Download Sery Link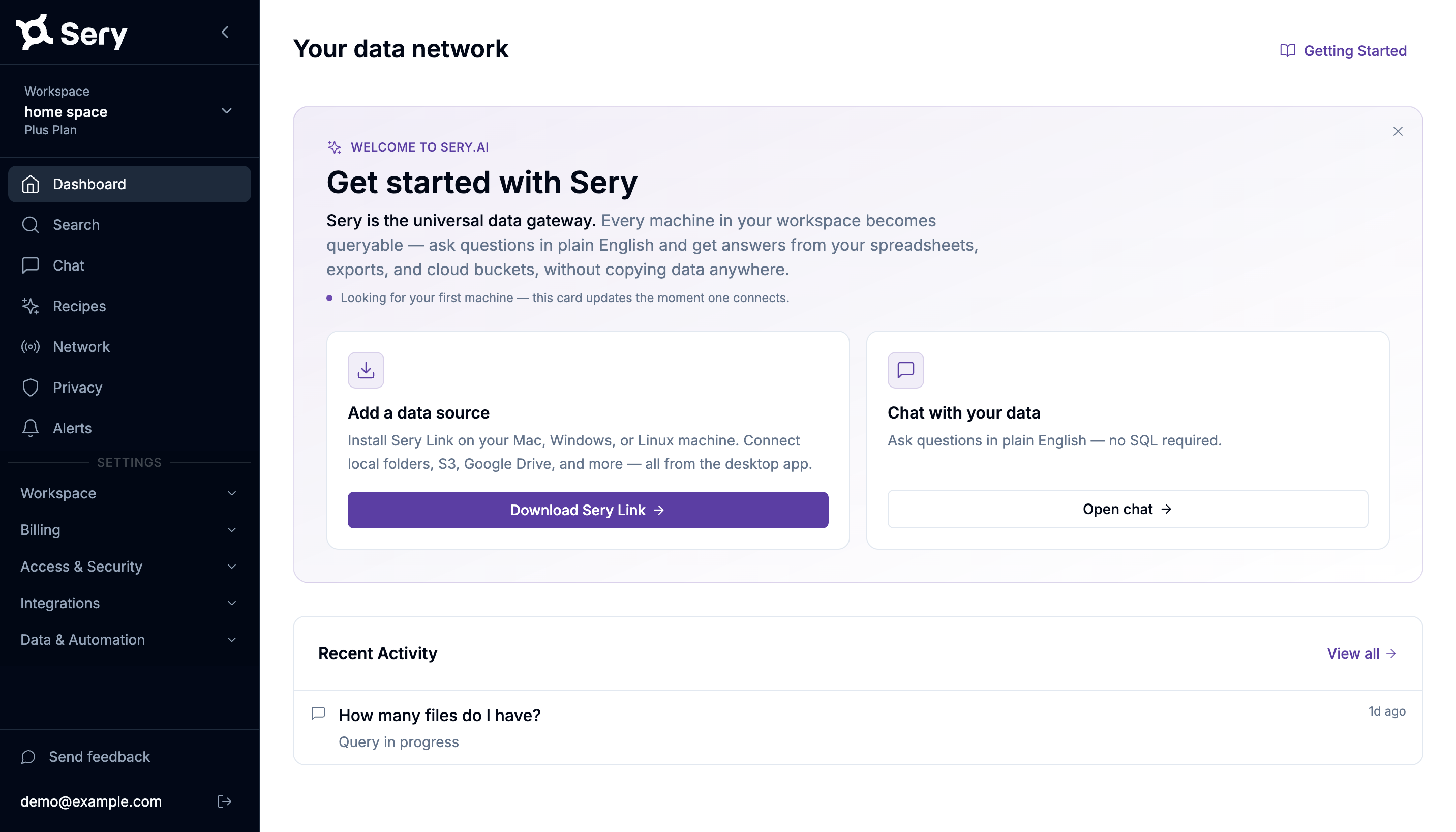
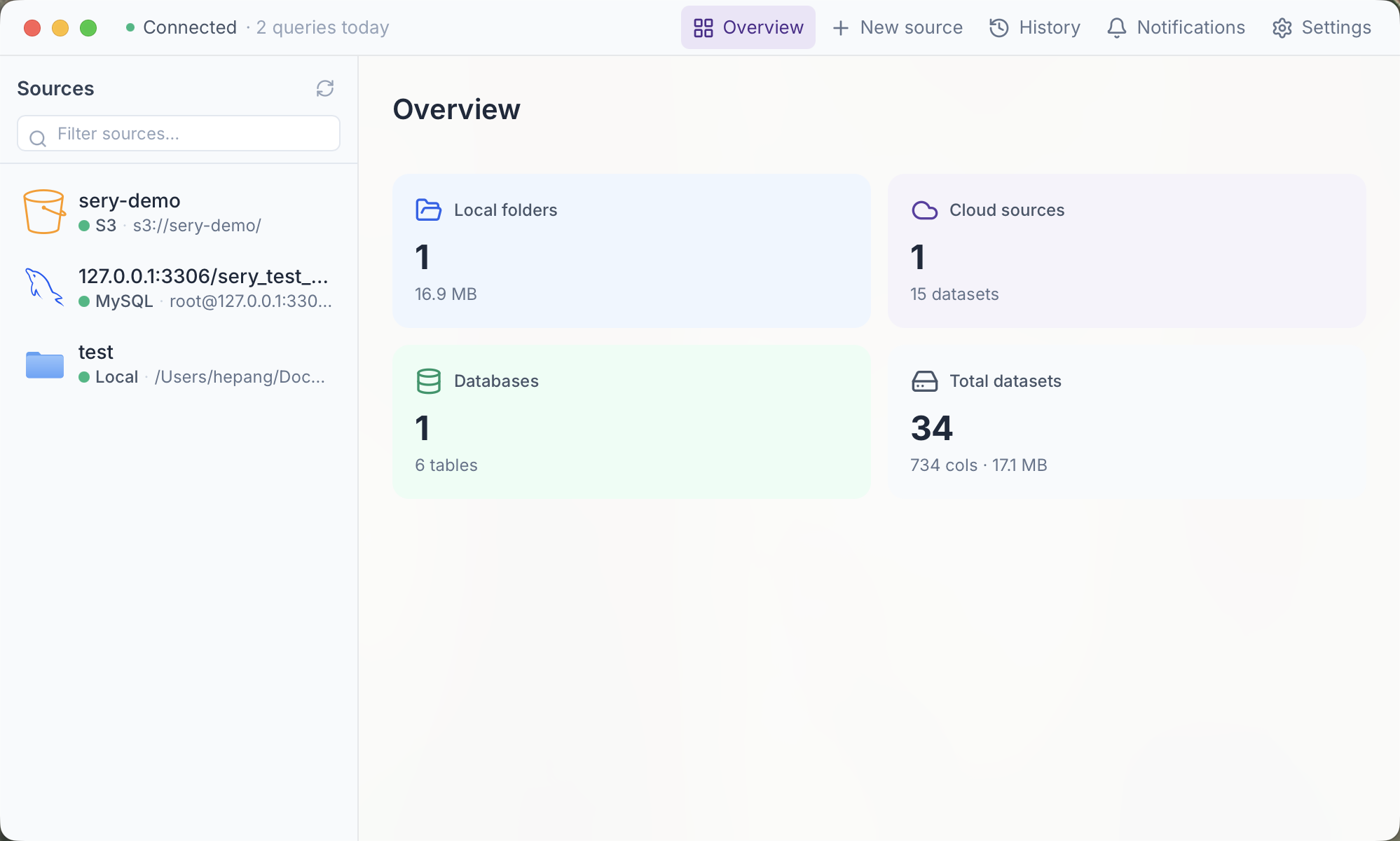
Dashboard · your workspace
Sign in at app.sery.ai to create your workspace, connect your machines into one private network, and chat with AI across everything. SQL runs back on your machines; only the answer travels.
Open the web app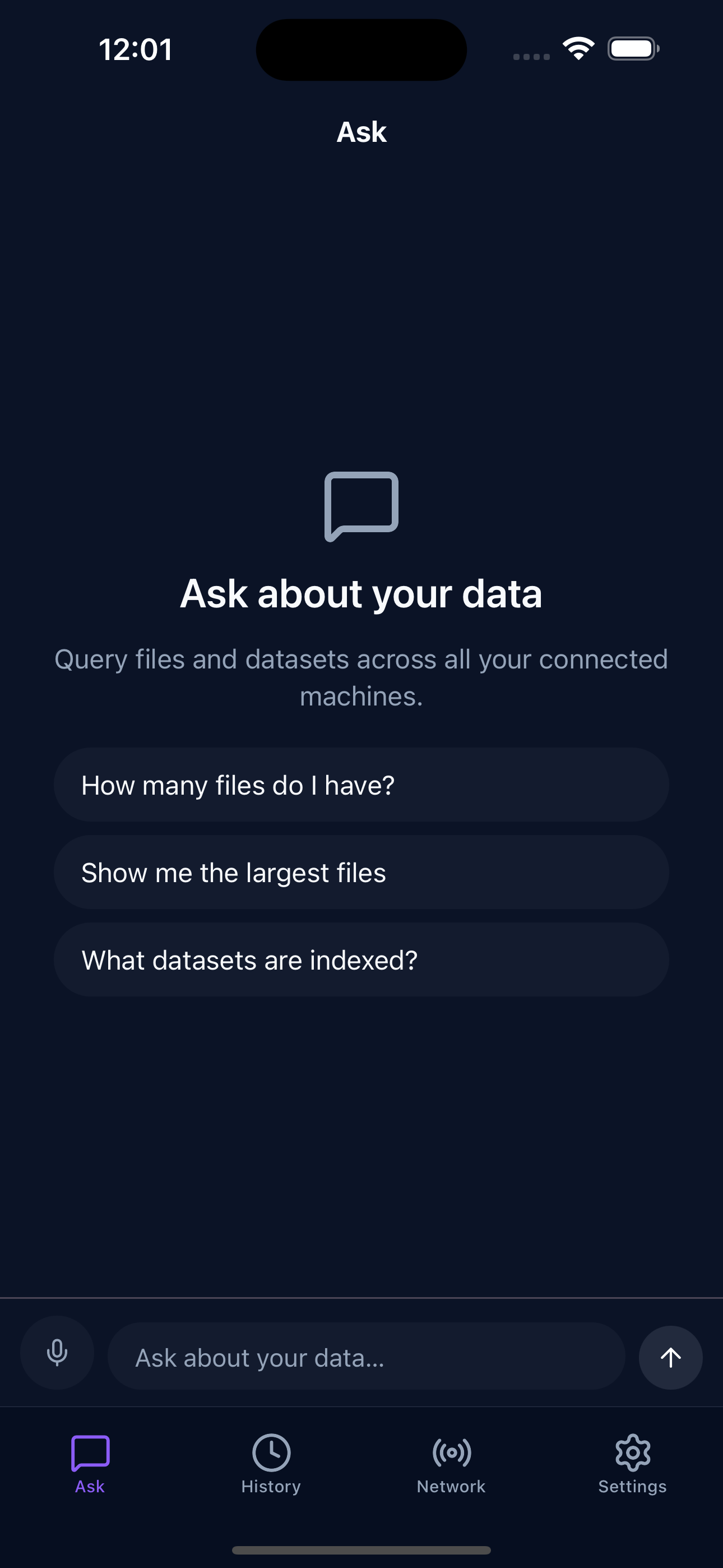
Sery Snap · ask by voice
The easiest way in. Hold the mic, ask out loud, and get answers from your machines — no laptop open, no SQL. iOS & Android.
Scan to get Sery Snap · iOS & AndroidYou have the data. You just can't get answers from it.
Your files and databases are scattered across a laptop, a few cloud buckets, and a database or two. The tools that find your files don't understand your data. The tools that understand your data want you to upload it first.
Generic file search
- —Finds files by name; can't tell you what's inside them or answer a question
- —Knows nothing about your databases or cloud buckets
- —One disk per search; no way to span machines or remote sources
Cloud AI & BI tools
- —Upload everything first — your files become someone else's problem
- —Monthly billing on row counts; a seat for every teammate
- —A privacy headache for files that legally can't leave the office
Sery: a private data agent on your own machine
Connect all 16 of your file stores and databases once. From then on, find, preview, and ask AI across every one of them — in plain English, running locally. Nothing uploaded. Nothing per-seat. Works across every machine you own.
The workflow
Connect everything. Then just ask.
No SQL to write, no dashboards to build, no upload step. Point Sery at your sources once — after that you ask a question and get an answer back, with the data never leaving your machine.
- 1
Connect your sources
Local folders, S3, Drive, SFTP, Postgres, Snowflake — 16 source types, added once.
- 2
Ask in plain English
Type it or say it — from the dashboard or Sery Snap. No query language to learn.
- 3
Get the answer — locally
Sery runs the query on each machine and brings back only the answer. Raw files never move.
For example
“Which client contracts expire in the next 90 days?”
“8 contracts — 5 in your S3 legal/ bucket and 3 in local Drive. The earliest is Acme Corp, expiring in 12 days…”
Why Sery
Your data, your machine, your moat.
Sery is built so the things that usually make data + AI risky — uploads, vendor lock-in, per-seat bills — simply don't apply.
Private by architecture
Raw data never leaves your machine. The cloud only ever sees catalog metadata and your questions — never file contents. Works offline, and it's open source (AGPL) you can audit.
No upload tax, no per-seat
Free to start. One flat $19.99/mo unlocks AI chat across your whole network — no row-count billing, no warehouse to feed, no charge per teammate or per machine.
Compounds across machines
Every machine and source you add joins one private network. Ask once, get answers from all of them. The more you connect, the more Sery is worth — without anything pooling in the cloud.
Who it's for
Built for people whose data can't go to the cloud.
If your files are confidential, regulated, or just too scattered to upload, Sery puts AI to work on them where they already live.
Law firms
Search contracts, discovery, and client files — summarised without leaving the office.
Learn moreAccountants
Ask across ledgers, statements, and client spreadsheets — without uploading a thing.
Learn moreHealthcare
Records and charts stay on-prem; AI still helps you find and reason across them.
Learn moreAnalysts & founders
CSVs, Parquet, and databases across S3 and local — answers without a warehouse.
See all use casesOne app · 9 file stores · 7 databases · 16 sources in total
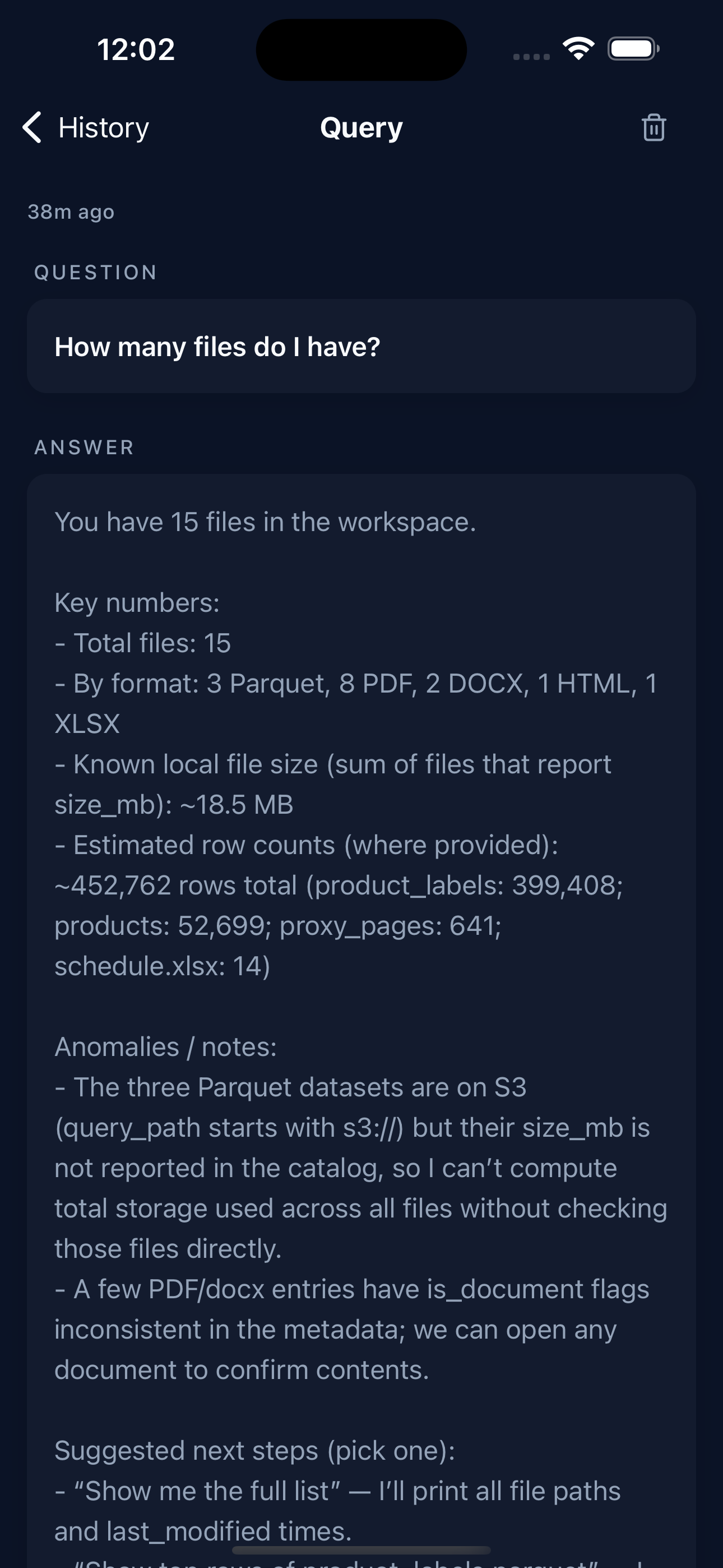
Ask your data from your phone
Hold the mic button and ask in plain English. Sery Snap reaches every machine in your workspace and returns the answer — no typing, no SQL, no laptop open.
- Hold-to-record voice input — speak your question, get a plain-English answer
- Sees every machine in your workspace — query across all of them at once
- Full conversation history — revisit any answer, any time
Install
One line. Then it's yours.
Native installers for macOS, Windows, and Linux. No account, no login, no “set up your workspace” first. Run the install and start connecting your data.
$ brew install seryai/tap/sery-linkor universal installer: curl -fsSL https://sery.ai/install.sh | sh
Give AI your data — without giving it away.
Free, open source, runs on your machine. Connect 16 file stores and databases, preview and query without downloading, and let AI reason across all of it — locally. Add Sery to a second machine? Plus ($19.99/mo) connects them and adds AI chat across everything. 7-day free trial, no card.